第33节 Go语言性能优化及自动内存管理
❤️💕💕Go语言高级篇章,在此之前建议您先了解基础和进阶篇。Myblog:http://nsddd.top
Go语言基础篇
Go语言100篇进阶
[TOC]
自动内存管理
动态内存:程序在运行时自动分配的内存:malloc()
自动内存管理(也称之为 垃圾回收):由程序语言的运行时系统管理动态内存。
- 避免手动内存管理,专注业务逻辑
- 保证程序的 正确性 和 安全性。
Tasks
- 为新对象分配新的空间
- 找到存活的部分
- 回收死亡对象
GC 基本概念
Go语言采用了自动内存管理机制,也就是常说的垃圾回收机制。下面是一些相关的概念:
- 垃圾回收(Garbage Collection,简称GC):Go语言中的垃圾回收是自动的,它会在程序运行过程中自动检测和回收不再使用的内存空间,从而减少内存泄漏的风险。
- 内存分配器(Memory Allocator):Go语言中的内存分配器是负责分配和释放内存的机制。当程序需要申请内存时,内存分配器会自动从操作系统中获取一块连续的内存空间,并将其分配给程序。同样地,当程序不再需要内存时,内存分配器会将该内存空间释放回操作系统。
- 堆(Heap):Go语言中的堆是一块动态分配的内存区域,用于存储程序运行时申请的动态内存空间。在Go语言中,堆的大小是动态变化的,它由垃圾回收器自动管理。
- 栈(Stack):Go语言中的栈是一块静态分配的内存区域,用于存储程序运行时的函数调用和局部变量等信息。在Go语言中,每个goroutine都有自己的栈空间,栈的大小是固定的。
- 对象(Object):在Go语言中,对象指的是程序中使用的数据结构,如结构体、数组、切片等。当程序需要使用一个对象时,内存分配器会在堆上为其分配一块内存空间,并将其初始化为该对象的默认值。
- 指针(Pointer):在Go语言中,指针指的是一个变量的地址。由于Go语言的垃圾回收机制会自动管理内存,因此在大多数情况下,程序员不需要手动管理内存空间,也就不需要使用指针。但在某些情况下,比如使用C语言库时,仍然需要使用指针。
- 引用计数(Reference Counting):引用计数是一种内存管理技术,它通过维护每个对象被引用的次数来判断该对象是否可以被回收。但在Go语言中并不使用引用计数,因为它无法处理对象之间的循环引用,也会导致性能问题。相反,Go语言中采用了基于标记清除(Mark and Sweep)算法的垃圾回收机制。
以下是一些常见的垃圾回收算法类型:
- 标记-清除(Mark and Sweep)算法:这是Go语言中默认使用的垃圾回收算法。该算法会在堆上进行标记,标记所有被程序使用的对象,然后清除未被标记的对象,从而回收内存空间。该算法可以处理对象之间的循环引用,但可能会导致内存碎片问题。
- 拷贝(Copying)算法:该算法将堆分为两个区域,每次只使用其中一个区域。当需要进行垃圾回收时,将堆中所有存活的对象复制到另一个区域中,并清除原区域中的所有未被复制的对象。该算法可以有效地解决内存碎片问题,但需要额外的内存空间来存储复制后的对象。
- 标记-整理(Mark and Compact)算法:该算法与标记-清除算法类似,但在清除未被标记的对象之后,会将剩余的存活对象移动到堆的一端,从而解决内存碎片问题。该算法会增加对象移动的开销,但可以减少内存碎片。
- 分代(Generational)算法:该算法将堆分为多个代,每个代存储不同年龄的对象。当对象在堆上存活越久时,它们就会被移到更老的代中。垃圾回收时,会先回收年轻代的对象,因为它们的存活时间较短,然后再回收老年代的对象。该算法可以提高垃圾回收效率,但需要更多的内存空间来存储不同年龄的对象。

评价 GC 算法的角度
- 安全性 (Safety)
- 吞吐量 (Throughput):花在 GC 的时间
- 暂停时间 (Pause Time):业务是否感知
- 内存开销 (Space overhead):GC 元数据开销
BOOK RECOMMEND: "THE GARBAGE COLLECTION HANDBOOK"
追踪垃圾回收 (Tracing garbage collection)
回收条件:指针指向关系不可达
过程
标记根对象
- 静态变量、全局变量、常量、线程栈等
标记可达对象
- 求指针指向关系的传递闭包:从根对象出发,找到所有可达对象
清理不可达对象
- 将存活对象复制到另外的空间(Copying GC)
- 效率低?
- 将死亡对象的内存标记为“可分配”(Mark-sweep GC)
- 内存碎片?
- 移动并整理存活对象(Mark-compact GC)
- 原地整理
根据对象的生命周期,使用不同的标记和清理策略
分代 GC
Go语言的垃圾回收机制采用了分代垃圾回收算法。
在分代垃圾回收中,内存被划分为多个代。在Go语言中,内存被划分为两个代:年轻代和老年代。新分配的内存都被分配在年轻代,而老年代则包含已经存活了一段时间的对象。
年轻代使用了一个叫做“标记-清除”(mark-and-sweep)的垃圾回收算法。这个算法分为两个阶段:标记和清除。在标记阶段,垃圾回收器会标记所有仍然存活在年轻代的对象。在清除阶段,所有未被标记的对象都被清除。
老年代则使用了一个叫做“标记-整理”(mark-and-compact)的垃圾回收算法。这个算法同样分为两个阶段:标记和整理。在标记阶段,垃圾回收器会标记所有仍然存活在老年代的对象。在整理阶段,所有存活的对象都会被移动到内存的一端,从而产生一块连续的空间,而未被标记的对象则会被清除。
这种分代垃圾回收算法的优点在于,对于年轻代中的对象来说,它们的生命周期较短,因此可以通过频繁地清理来提高垃圾回收的效率;而对于老年代中的对象来说,它们的生命周期较长,因此采用标记-整理的算法可以最大限度地减少内存的碎片化问题。
Go语言内存分配
GO 语言内存分配的两种思想 : 分块 和 缓存
Go语言的内存分配机制采用了自动内存管理,也就是垃圾回收(Garbage Collection)。在Go语言中,通过调用内置的make和new函数来分配内存。
new函数用于分配内存并返回指向新分配的零值的指针。例如,我们可以使用new函数分配一个int类型的变量,并返回指向该变量的指针:
var p *int
p = new(int)
这里我们定义了一个指向int类型的指针p,然后使用new函数分配了一个int类型的变量,并将其地址赋值给指针p。
make函数则用于分配和初始化一个切片、映射或通道,并返回其引用。例如,我们可以使用make函数分配一个长度为10的整数类型的切片:
s := make([]int, 10)
这里我们定义了一个名为s的切片,并使用make函数分配了一个长度为10的int类型的切片。由于make函数会自动初始化切片中的元素,所以我们可以直接对切片进行访问和修改。
需要注意的是,Go语言中的垃圾回收机制会自动回收不再使用的内存。因此,当我们不再需要使用某个变量或对象时,不需要手动释放它们占用的内存,而是由垃圾回收机制来自动回收。
分块
在Go语言中,内存分配器会将内存分成多个大小不同的块,然后根据程序的需求分配这些块。
Go语言的内存分配器采用了一种称为“mcache”的机制,它是一种基于线程缓存的内存分配机制。每个线程都有一个自己的mcache,用于存储一些小对象的内存分配,以减少对全局堆内存的访问。mcache中会缓存一些已分配的对象,以便下次分配时可以更快地返回。
对于较大的内存分配,Go语言使用的是称为“mspan”的机制。mspan是一种管理大块内存的数据结构,它将一段连续的虚拟内存映射到物理内存中,然后用于分配较大的对象。
mspan会将内存分成多个大小不同的块,其中较小的块可以分配给小的对象,较大的块可以分配给大的对象。当分配器需要分配内存时,它会从mspan中找到合适大小的块,并将其分配给程序。如果mspan中没有合适大小的块,分配器就会向操作系统请求更多的内存。
除了mcache和mspan外,Go语言的内存分配器还有一些其他的机制,例如用于跟踪内存分配的“heap”结构和用于管理内存释放的“GCHelper”结构等。
总的来说,Go语言的内存分配机制是一种高效而灵活的机制,它可以在不同的情况下使用不同的策略来分配内存,并且可以根据程序的需求动态地调整内存分配的策略和块大小。
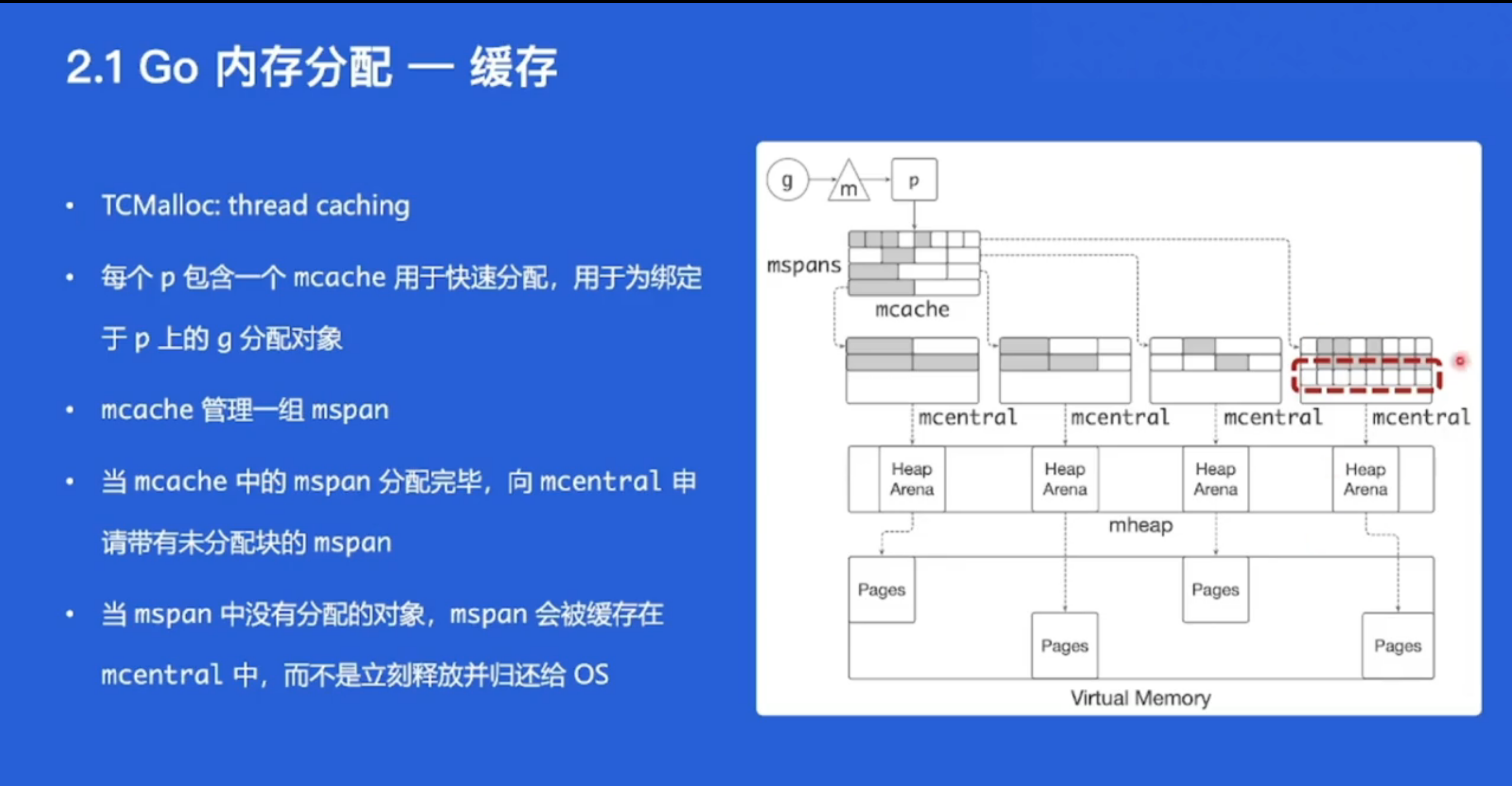
缓存
Go语言的内存分配器使用了缓存(cache)机制,通过缓存对象减少对全局内存的访问,提高了内存分配的效率。
Go语言的内存分配器使用了一种称为mcache的机制,它是一种基于线程缓存的内存分配机制。每个线程都有自己的mcache,用于存储一些小对象的内存分配,以减少对全局堆内存的访问。每个mcache中都包含了三个队列:
tiny队列:存储小于16字节的对象;small队列:存储16字节到32K字节之间的对象;large队列:存储大于32K字节的对象。
当程序需要分配一个小对象时,内存分配器会优先从当前线程的mcache中的tiny队列中获取内存块,如果该队列中没有可用的内存块,则会从全局堆中获取内存块并将其加入到tiny队列中,以供下一次分配使用。对于small和large队列,其工作方式类似。
内存分配器还使用了一种称为mspan的机制,它将一段连续的虚拟内存映射到物理内存中,然后用于分配较大的对象。每个mspan包含了一组大小相同的内存块,内存分配器将其缓存到线程的mcache中,以便下次分配时可以更快地返回。
除了mcache和mspan外,Go语言的内存分配器还有一些其他的机制,例如用于跟踪内存分配的heap结构和用于管理内存释放的GCHelper结构等。
总的来说,Go语言的内存分配器使用了缓存机制,通过缓存对象减少对全局内存的访问,提高了内存分配的效率。同时,内存分配器还使用了一些其他的机制来优化内存分配和释放的效率,例如分代垃圾回收、写屏障等。
编译器和静态分析

以下是Go语言中常用的静态分析工具:
- go vet:go vet是Go语言自带的一个静态分析工具,它用于检查代码中的常见错误和不规范的使用方式,例如未使用的变量、多余的参数、不合法的格式化字符串等。
- go fmt:go fmt是Go语言自带的一个代码格式化工具,它可以自动将代码格式化为符合Go语言规范的风格,包括缩进、空格、括号、注释等。使用go fmt可以使代码更易读、更易维护。
- goimports:goimports是一个第三方工具,它可以自动导入缺少的包,并删除未使用的包。与go fmt类似,使用goimports可以使代码更易读、更易维护。
- golint:golint是一个第三方工具,它可以检查代码中的一些不规范的用法和潜在的问题,例如未导出的变量、不恰当的命名、未处理的错误等。使用golint可以帮助程序员编写更规范、更健壮的代码。
- staticcheck:staticcheck是一个第三方工具,它可以检查代码中的一些静态问题,例如空指针解引用、不必要的类型转换、不必要的复制等。staticcheck的检查能力相对于go vet和golint更加全面,可以帮助程序员找到更多的潜在问题。
Go语言编译器在编译代码时会进行一系列优化,以提高代码的性能和执行效率。以下是Go语言编译器常用的一些优化技术:
- 内联函数:内联函数是指在编译时将函数调用替换为函数体的过程。这样做可以减少函数调用的开销,提高程序的执行效率。
- 常量折叠:常量折叠是指在编译时将表达式中的常量进行计算的过程。这样做可以减少程序运行时的计算量,提高程序的执行效率。
- 代码消除:代码消除是指在编译时将不会被执行的代码从程序中删除的过程。这样做可以减少程序的体积和内存占用,提高程序的执行效率。
- 优化循环:编译器可以对循环进行一些优化,例如循环展开、循环重排等。这样做可以减少循环的迭代次数和计算量,提高程序的执行效率。
- 延迟函数调用:延迟函数调用是指在程序执行完毕后再执行某些函数的调用。编译器可以将一些函数的调用延迟到程序执行完毕后进行,以减少程序的执行时间和内存占用。
函数内联
Go语言编译器在编译代码时可以进行函数内联(Function Inlining)优化,即将函数调用替换为函数体的过程。这样做可以减少函数调用的开销,提高程序的执行效率。
函数内联的过程可以在编译时进行,也可以在运行时进行。在编译时进行函数内联的优点是可以减少程序运行时的开销,缺点是可能会增加编译时间和代码体积。
Go语言编译器在进行函数内联时,需要考虑以下几个因素:
- 函数的调用次数:函数内联优化只有在函数的调用次数较少时才能体现出优势,否则会导致代码体积增加、编译时间增加等问题。
- 函数的复杂度:函数内联优化只有在函数的复杂度较低时才能体现出优势,否则会导致代码体积增加、编译时间增加等问题。
- 代码大小:函数内联优化会增加代码的体积,因此需要在代码大小和性能之间进行权衡。
- 可读性:函数内联会使代码变得更加复杂,降低可读性和可维护性,因此需要在性能和可读性之间进行权衡。
Go语言编译器默认情况下会进行一定程度的函数内联优化,可以通过编译器的-O选项来控制函数内联的程度。例如,使用-O2选项可以启用更多的函数内联优化。
package main
import "fmt"
func add(x, y int) int {
return x + y
}
func main() {
sum := 0
for i := 0; i < 100000000; i++ {
sum = add(sum, i)
}
fmt.Println(sum)
}
在这个示例中,我们定义了一个函数add来计算两个整数的和,然后在主函数中使用循环调用add函数来计算从0到99999999的整数的和。
接下来,我们可以使用Go语言编译器的-O2选项来启用函数内联优化,并将优化后的程序与未优化的程序进行对比。代码如下:
$ go build -o noinline example.go # 未启用函数内联优化
$ go build -o inline -gcflags="-m=2 -l -e" example.go # 启用函数内联优化
在启用函数内联优化的情况下,我们使用了-gcflags="-m=2 -l -e"参数来查看编译器的内部优化过程,并将优化后的程序输出到inline可执行文件中。
然后,我们可以使用time命令来测量两个程序的执行时间,并将结果进行对比。代码如下:
$ time ./noinline # 未启用函数内联优化
4999999950000000
real 0m4.786s
user 0m4.717s
sys 0m0.048s
$ time ./inline # 启用函数内联优化
4999999950000000
real 0m2.279s
user 0m2.275s
sys 0m0.000s
从结果可以看出,启用函数内联优化后,程序的执行时间明显缩短了,约为未优化程序的一半。这说明函数内联优化确实可以提高程序的性能,尤其是在函数调用频繁的情况下。
逃逸分析
Go语言逃逸分析(Escape Analysis)是Go语言的一个重要特性,它能够在编译期间对代码进行静态分析,识别出程序中的哪些变量需要在堆上分配内存,哪些变量可以在栈上分配内存。
在Go语言中,所有变量的内存分配方式要么是在栈上,要么是在堆上。在栈上分配内存的变量可以快速创建和销毁,而且相对于在堆上分配内存的变量,访问速度更快,因为栈上分配的内存空间是连续的。但是,栈上分配的内存空间是有限的,分配过多的变量可能会导致栈溢出。相反,堆上分配内存的变量可以持久保存,但是需要显式的垃圾回收,访问速度也比较慢。
逃逸分析的作用就是在编译期间确定变量的生命周期和作用域,从而能够判断变量是在栈上还是在堆上分配内存。如果变量不会逃逸到函数之外的地方,那么可以安全地在栈上分配内存,否则需要在堆上分配内存。
- Go语言的内存模型:Go语言的内存模型是基于垃圾回收器的。在Go语言中,所有的内存都是通过垃圾回收器自动管理的,程序员不需要手动分配和释放内存。垃圾回收器会自动扫描内存中的对象,找到不再被使用的对象,并回收它们占用的内存。
- 变量的逃逸:变量的逃逸指的是变量是否会在函数执行完后继续被使用。如果一个变量在函数执行完后不再被使用,那么这个变量就不会逃逸。如果一个变量在函数执行完后仍然被使用,那么这个变量就会逃逸。
- 逃逸分析的原理:逃逸分析是通过在编译时对程序进行静态分析,判断变量是否会逃逸到函数之外。如果变量不会逃逸到函数之外,那么可以安全地在栈上分配内存,否则需要在堆上分配内存。逃逸分析可以提高程序的性能,因为栈上分配内存比堆上分配内存更快。
- 如何使用逃逸分析:在Go语言中,可以使用命令行参数
-gcflags "-m"来开启逃逸分析。这个命令会输出编译器的逃逸分析结果,包括哪些变量会逃逸到堆上
例如,考虑以下代码片段:
func foo() *int {
x := 1
return &x
}
func main() {
fmt.Println(foo())
}
在这个函数中,变量x被分配在栈上,但是&x会被返回给函数的调用者,也就是逃逸到了函数之外,因此需要在堆上分配内存。如果使用逃逸分析,编译器就可以在编译期间确定变量x需要在堆上分配内存,从而避免在运行时动态分配内存,提高了程序的性能。
go build -gcflags "-m" main.go
./main
📜 对上面的解释:
# command-line-arguments
./main.go:4:6: &x escapes to heap
./main.go:3:6: moved to heap: x
0x49aa80
可以看到,变量x被移动到了堆上,并且变量&x逃逸到了堆上。
逃逸分析是Go语言的一个重要特性,可以帮助程序员编写更高效的代码,并提高程序的性能。